
Efficient Gather-and-scatter Feed-forward Network Kernel with Triton
In our recent work Learn to be efficient: Build structured sparsity in large language models, we propose a novel method to build structured sparsity in large language models. Through jointly training of router and LLM, we achieves a better trade-off between sparsity and accuracy.
Unfortunately, the current Pytorch doesn’t provide an efficient implementation of sparse feed-forward network. To translate the theoretical FLOPs reduction into real speedup, we need to implement a kernel by ourselves.
This post is the continuation of Efficient Gather-and-scatter Matrix Multiplication Kernel with Triton. We will implement an efficient gather-and-scatter feed-forward network kernel with Triton. Click here to jump to the final implementation code.
Introduction
Feed-forward network normally consists of three operations:
- Linear transformation, mapping input to higher intermediate representation.
- Activation function, and an optional element-wise multiplication (e.g. Llama).
- Linear transformation, mapping intermediate representation back to feature space.
We’ve already implemented the first two operations in the previous post, where we solve the uncoalesced memory access problem by storing a column major matrix, however, the thing gets trickier for the third operation.
Here is a simple illustration of the FFN operation:
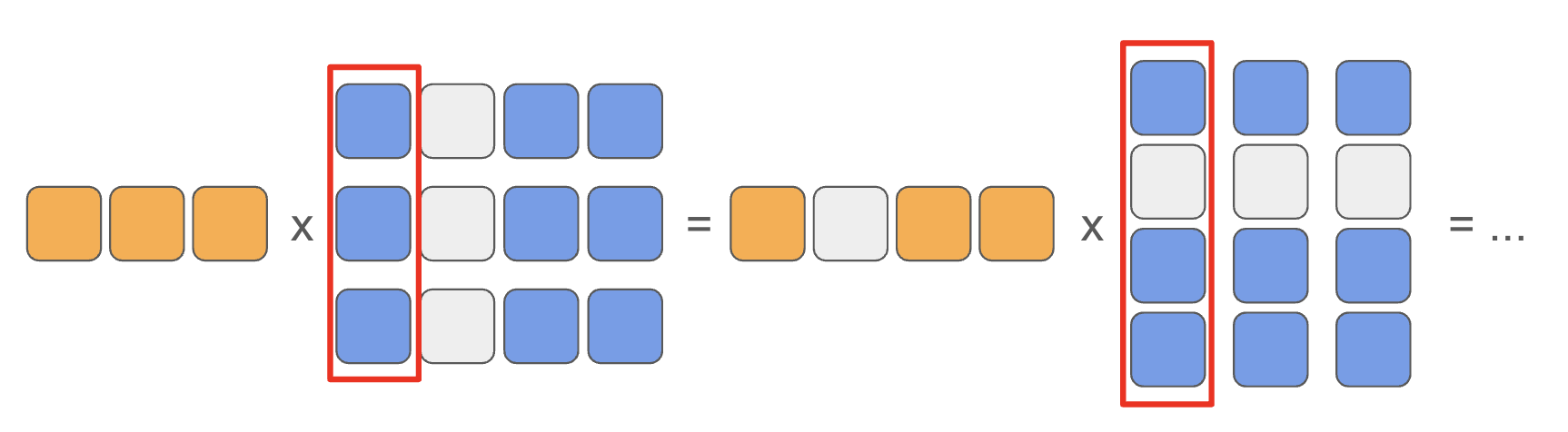
In matrix multiplication, we take each column of the weight matrix to compute dot product with the input. In the upper mapping step (second step), the router selects by columns, so the data loaded during dot product is still a complete array.
However, in the third operation, we need to select by rows, which breaks the coalesced memory access. Therefore, to achieve efficient sparse FFN, we also need to change the way we calculate the GEMM on third step.
Design
Obviously, coalesced memory access is our first priority, so we need to load the weight row by row. But in that way, we cannot keep the accumulator inside one threadblock.
Suppose the intermediate vector is in 1xN, instead of computing dot product between two vectors, 1xN and Nx1 across K threadblocks, now we are calculating the element-wise product between one element and a row of the weight matrix (1xK), which will output an array with the same length as a row (1xK).
Then, we need to add this array to a shared accumulators array in 1xK. That means, the accumulators have to be in the global memory, and it might be accessed simultaneously by multiple threadblocks.
Here is an illustration of how it works:
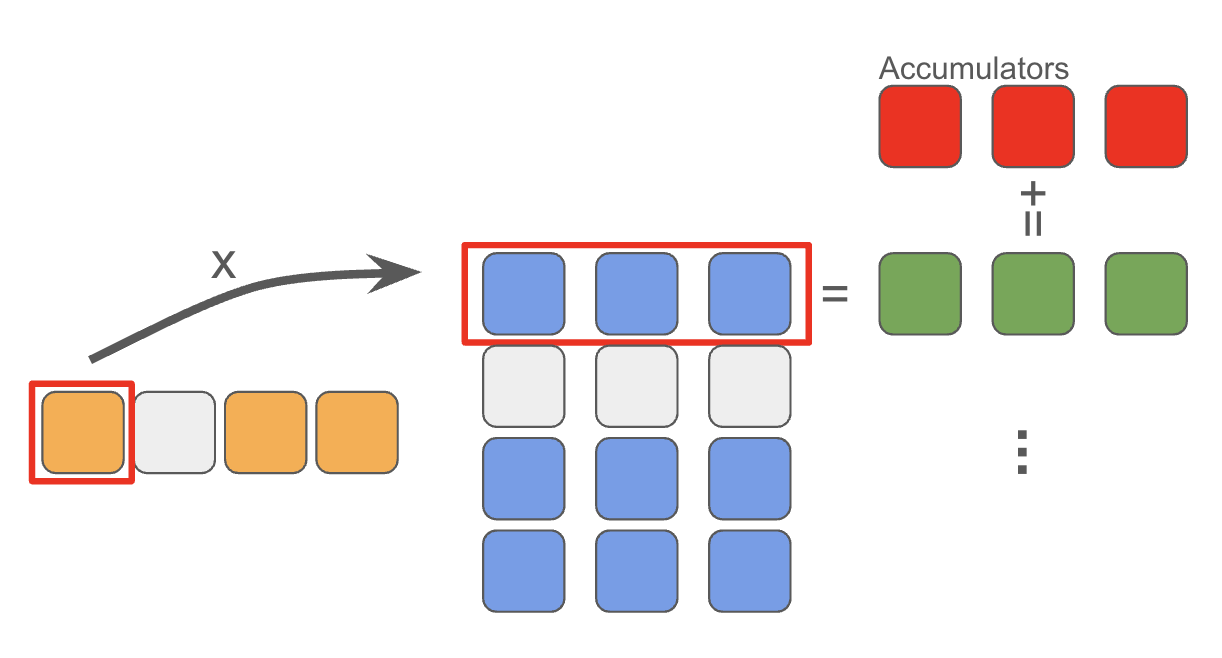
Basically, the implementation of mapping down includes two steps for each threadblock:
- Calculate the element-wise product between one element and a row of the weight matrix (1xK), which will output an array with the same length as a row (1xK).
- Add the array to the accumulators in global memory, and use
tl.atomic_addto avoid race condition.
I know using tl.atomic_add sounds like a bad idea, but as far as we tested, it didn’t become a bottleneck. My guess is that the accumulators are short enought to be kept in the L2 cache, and it doesn’t actually read and write to the global memory frequently.
Also, because the conflict of atomic operation is inter-threadblock, and GPU will schedule other threadblocks if the current one is pending, the latency is perfectly hidden.
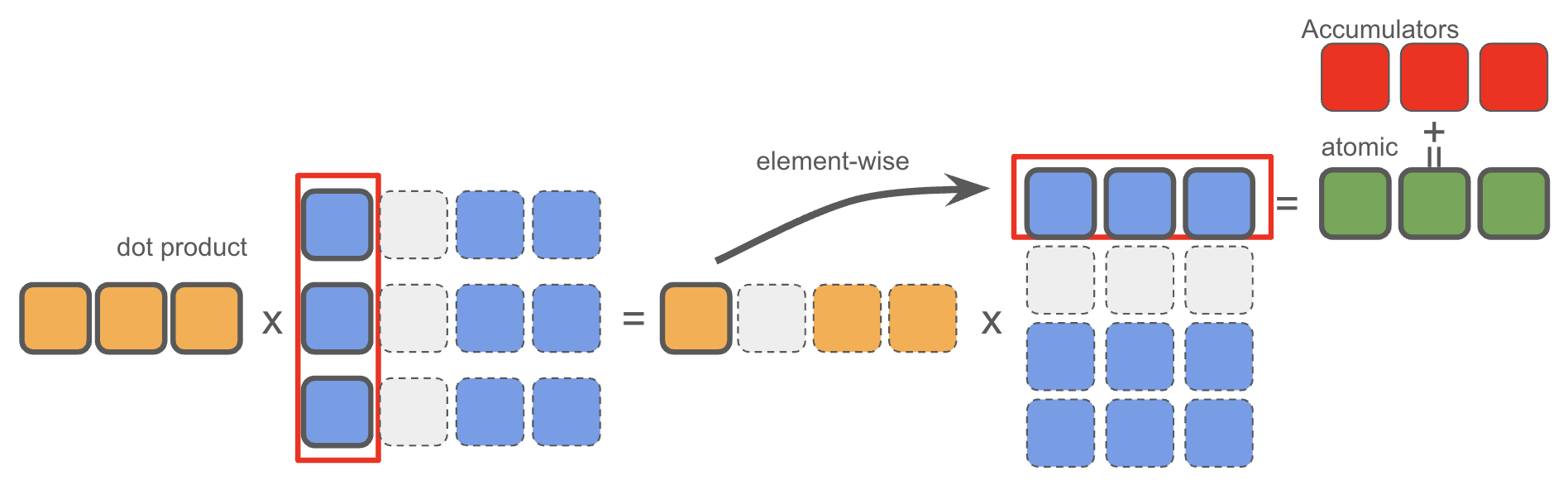
What’s more, because now every threadblock only need one element from the output of upper mapping step, we can completely fuse the three steps without any write-back to the global memory before we get the final result.
Here is the illustration of the whole process from a threadblock’s perspective:
Final Implementation
Below is the final implementation of the gather-and-scatter feed-forward network kernel. We take GPT-2 FFN as an example, but it also works for others like Llama-2 FFN, just some minimal changes to the accumulator.
@triton.autotune(
configs=get_cuda_autotune_config(),
key=['M', 'N', 'K'],
)
@triton.jit
def indexed_ffn_fused_kernel(
# Pointers to matrices
a_ptr, b_ptr, d_ptr, e_ptr, # e is the accumulators in global memory
l_ptr,
# Matrix dimensions
# ideal a (M, K), b (K, L), c (M, L), d (L, K), index (L)
# actual a (M, K), b (N, K), c (M, L), d (N, K), index (L)
M, N, K,
L,
# The stride variables represent how much to increase the ptr by when moving by 1
# element in a particular dimension. E.g. `stride_am` is how much to increase `a_ptr`
# by to get the element one row down (A has M rows).
stride_am, stride_ak, # M x K
stride_bn, stride_bk, # N x K
stride_dn, stride_dk, # N x K
# Meta-parameters
BLOCK_SIZE_M: tl.constexpr, BLOCK_SIZE_N: tl.constexpr, BLOCK_SIZE_K: tl.constexpr, #
GROUP_SIZE_M: tl.constexpr, #
ACTIVATION: tl.constexpr #
):
"""Kernel for computing the matmul C = A x B.
A has shape (M, K), B has shape (K, N) and C has shape (M, N)
"""
# -----------------------------------------------------------
# Map program ids `pid` to the block of C it should compute.
# This is done in a grouped ordering to promote L2 data reuse.
# See above `L2 Cache Optimizations` section for details.
pid = tl.program_id(axis=0)
num_pid_m = tl.cdiv(M, BLOCK_SIZE_M)
num_pid_n = tl.cdiv(L, BLOCK_SIZE_N)
num_pid_in_group = GROUP_SIZE_M * num_pid_n
group_id = pid // num_pid_in_group
first_pid_m = group_id * GROUP_SIZE_M
group_size_m = min(num_pid_m - first_pid_m, GROUP_SIZE_M)
pid_m = first_pid_m + (pid % group_size_m)
pid_n = (pid % num_pid_in_group) // group_size_m
# ----------------------------------------------------------
# Create pointers for the first blocks of A and B.
# We will advance this pointer as we move in the K direction
# and accumulate
# `a_ptrs` is a block of [BLOCK_SIZE_M, BLOCK_SIZE_K] pointers
# `b_ptrs` is a block of [BLOCK_SIZE_K, BLOCK_SIZE_N] pointers
# See above `Pointer Arithmetic` section for details
offs_am = (pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)) % M
offs_bn = (pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)) % L
offs_k = tl.arange(0, BLOCK_SIZE_K)
offs_bl = tl.load(l_ptr + offs_bn)
a_ptrs = a_ptr + (offs_am[:, None] * stride_am + offs_k[None, :] * stride_ak)
b_ptrs = b_ptr + (offs_bl[None, :] * stride_bn + offs_k[:, None] * stride_bk)
# -----------------------------------------------------------
# Iterate to compute a block of the C matrix.
# We accumulate into a `[BLOCK_SIZE_M, BLOCK_SIZE_N]` block
# of fp32 values for higher accuracy.
# `accumulator` will be converted back to fp16 after the loop.
accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)
for k in range(0, tl.cdiv(K, BLOCK_SIZE_K)):
# TODO: try (k + pid_n) % tl.cdiv(K, BLOCK_SIZE_K) to avoid congestion add
# Load the next block of A and B, generate a mask by checking the K dimension.
# If it is out of bounds, set it to 0.
a = tl.load(a_ptrs, mask=offs_k[None, :] < K - k * BLOCK_SIZE_K, other=0.0)
b = tl.load(b_ptrs, mask=offs_k[:, None] < K - k * BLOCK_SIZE_K, other=0.0)
# We accumulate along the K dimension.
accumulator = tl.dot(a, b, accumulator)
# Advance the ptrs to the next K block.
a_ptrs += BLOCK_SIZE_K * stride_ak
b_ptrs += BLOCK_SIZE_K * stride_bk
if ACTIVATION == "leaky_relu":
accumulator = leaky_relu(accumulator)
c = accumulator.to(tl.float32)
# no need to write back to the global memory
# -----------------------------------------------------------
# Iterate to compute a block of subE
# We put E block into a `[BLOCK_SIZE_M, BLOCK_SIZE_N]` block
# of fp32 values for higher accuracy.
# Require atomic add when writing to E results.
d_ptrs = d_ptr + (offs_bl[:, None] * stride_dn + offs_k[None, :] * stride_dk)
e_ptrs = e_ptr + (offs_am[:, None] * stride_am + offs_k[None, :] * stride_ak)
offs_em = (pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M))
offs_dn = (pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N))
for k in range(0, tl.cdiv(K, BLOCK_SIZE_K)):
# boundary check
d_mask = (offs_dn[:, None] < L) & (offs_k[None, :] < K - k * BLOCK_SIZE_K)
d = tl.load(d_ptrs, mask=d_mask, other=0.0)
e = tl.dot(c, d) # c is [BLOCK_SIZE_M, BLOCK_SIZE_N], d is [BLOCK_SIZE_N, BLOCK_SIZE_K]
# boundary check
e_mask = (offs_em[:, None] < M) & (offs_k[None, :] < K - k * BLOCK_SIZE_K)
# add to the accumulators
tl.atomic_add(e_ptrs, e, mask=e_mask)
d_ptrs += BLOCK_SIZE_K * stride_dk
e_ptrs += BLOCK_SIZE_K * stride_ak
We profiled on a single RTX 3090Ti, which has very limited memory bandwidth (~1TB/s) compared with HBM GPUs. The results shows that we achieve linear speedup with the increasing of sparsity (i.e. the portion of neurons that are not activated).
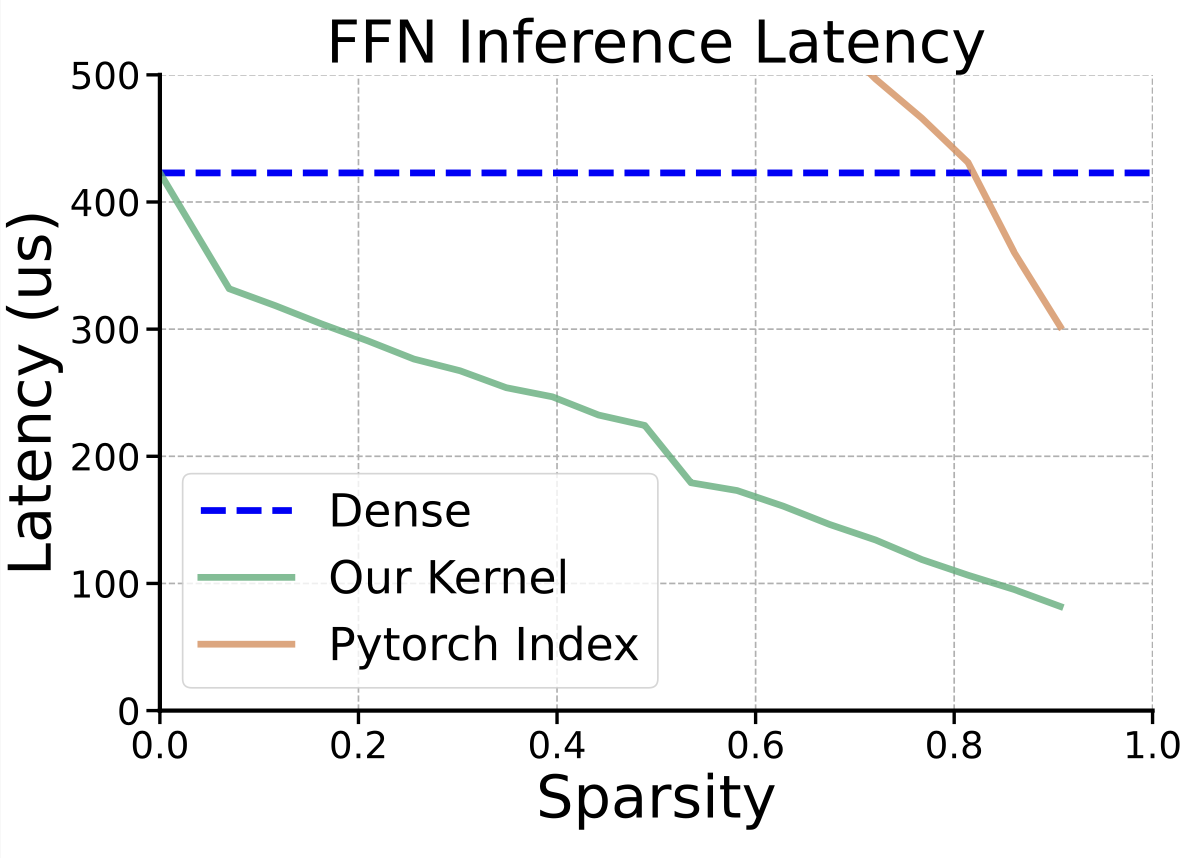
For more details, please refer to our paper.
Comments